
Case
实测可灵30普通人的导演梦成真了
这次更新了单次15s多分镜视频生成,多角色多语言对线k清晰度,一致性稳到离谱。来看这两个case,
这两个视频,第一个是图生视频,第二个是文生视频,两个视频的画面都更加具有电影感,而且都做出了分镜,第一个视频我给到的提示语是:
一名特工在夜晚的香港街头被人追,时不时回头看对方位置露出紧张的表情,最终一边跑一边从车门跳上一辆行驶中的电车,然后在行驶晃动的电车中走向车的后方,伴随着行驶的电车男人从电车后窗回头望停下来追不上他停下原地的另一个男人。紧张,快节奏,电影感。
在提示语里只是写出了剧情内容,完全没有告诉它需要在人物进行什么动作的时候,用什么样的镜头、什么样的景别以及什么样的镜头运动。可灵是自己做出了5个分镜。
我和我的编导朋友一拍即合,把一个个分镜拆解来看,看看可灵有没有导演思维。
第一个镜头可灵用了低角度追拍,人物迎着镜头冲向观众的动态把紧迫感拉满。同时可灵能够自己思考在画面中增加了很多和行人碰撞的场景,做出人物和环境的互动。

然后在手持晃动的跟拍镜头中,露出了人物一个有点虚焦的面部镜头。可灵知道我在提示词中写出的男主露出紧张的表情,选择用特写镜头来展现,这是电影节奏中的呼吸位。

第三个镜头,可灵又换了一个视角,展现了人物遇到一辆电车的场景。整个电车出现的位置并不突兀,而且能够感觉到人物下一秒就会跟电车做出互动。

第四个镜头,人物跳上车的站位和他上一个镜头的动作衔接也是对应上的,这里整个人物的动作以及镜头的设计,都很有真实感。

最后一个镜头是人物在车尾看到停下来追击他的男人,这里通过人物的过肩镜头来展现人物的位置关系,设计得也都非常自然。

能看得出来,可灵是明确知道在表现什么样的画面内容时,应该用什么样的构图、什么样的镜头运动以及什么样的景别。这些知识是导演需要具备的基础技术知识,可灵现在已经拥有了。
除了可以让可灵帮你自动做分镜之外,如果你已经有提前规划好的分镜,知道要如何安排自己的镜头,也可以用可灵 3.0 现在的自定义分镜功能。

在 15 秒内最多可以规划出 6 个分镜,可以选择每个分镜的时长,写好每个分镜的剧情内容。
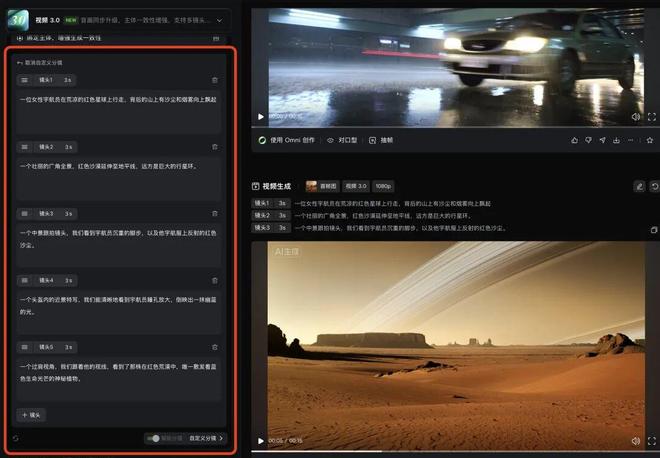
我按照上面这张图的分镜内容,做出了下面这个视频,每一个镜头的画面和时长,都是按照我规定的内容做出来的,尤其整个画面保持了非常强的风格一致性。
我们可以在一段15秒的视频里面设计多个人物的连续对话,而且能够做出以往 AI 视频很难做出来的人物正反打对话镜头,比如下面这个视频。
人物的对话非常自然,多个人物角色在做动作的同时,能保持说话时要求的情绪音色准确性,且表演细腻,同时对话镜头能保持较高的风格和人物的一致性。
可灵在控制分镜的剪辑时节奏也很好,很短的15秒视频真的很有那种冷幽默的感觉
也就是说,我们以后不需要一张图一张图地来固定人脸了,而是可以一组视频一组视频地去制作。
我还测试了几个不同风格的画面,每一种画面都能够保持严格的一致性,即使是比较风格化的动画制作,它也能够很好地保持下来。
从外景的容器堆场,到蓝红两台机甲的涂装细节,再到座舱内飞行员的制服,一致性保持得都非常好。九色鹿低头轻触凡人额头的动作,轻盈且带有仪式感,没有机械僵硬感。
动漫风格的人物动作没有变形成伪3D的感觉。仙侠动画中女主角飘逸的高马尾、淡蓝色的剑光,在 360 度大范围旋转镜头中始终保持着统一的形态。
而且可灵还能讲方言,在这个基础上,我又玩了一个很有意思的东西,在古装场景中,包装了一个非常有地域特点的、四川话风格的情侣对话场景,
本来你以为是一个比较正经的场面,结果两个人一开口,是比较接地气的四川话。地域特征一加上,人物就更加鲜活,整个画面就更加有戏剧感。
然后我又又又玩了一个比较复杂的场面,是港剧里经常能看到的粤语和英语掺杂在一起讲的场景。这里我直接使用的是文生视频。
这个视频我写的提示词是这样的,其实蛮抽象的,说实话这个复杂程度,我一个广东本地人都没读明白,但是可灵读明白了,
在一家办公室里,两个人在对话,A(被抢功者,崩溃又暴怒,声音发抖): 你居然当着 Boss 说那个 Strategy 是你想的?那份 Deck 我改了三十遍,凌晨三点还在调 Font!真系 Shameless(不要脸)到爆咯你!(注:语速很快,普通话带哭腔,英文词重读,粤语收尾带骂意)B(抢功者,轻蔑自信,反咬一口): Relax,我系 Lead 呀!没有我去 align 资源,你啲东西根本落唔到地,别咁玻璃心啦!唔好喺度嘈!(注:B全程半笑,眼神藐视,语气理所当然,最后一句用粤语强行压制对方)
除了方言之外,可灵的多国语言讲得也都很不错。我直接设计了一个三人场景,然后给他们每一个人都做了一个单人的切景分别讲中文、英文、韩语。不仅全程人脸保持了一致,而且语言、动作、神态表情做得都很不错。
即使是切近它自己生成的画面,镜头也都能够保持很高清晰度,人脸的细节什么的做得都很到位。
从界面上就可以看到,可灵 3.0 Omni 出现在之前我们介绍过的多模态视频编辑功能中可灵O1模型所在的位置,其实可灵3.0 Omni就是O1升级后的新版本,更加侧重视频编辑功能。
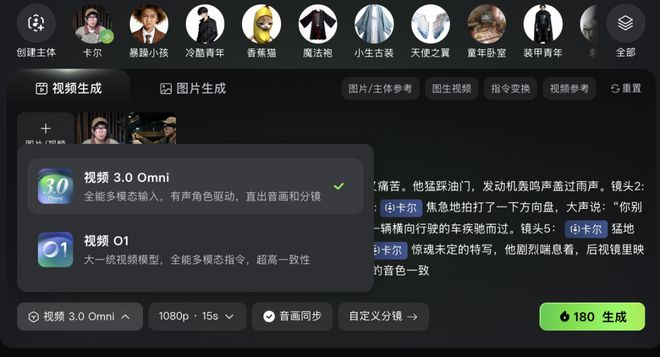
我可以在可灵 3.0 Omni 中上传自己的一段视频作为创建主体。然后后续使用这个主体来创建视频的话,它就可以很严格地保持音色的一致。
然后我用这个角色做了两段 15 秒的视频,并将它们拼接在了一起。从这两段视频中可以听到,我的角色保持的音色与我的原声一致,我自己听起来还是挺明显的。
固定音色是之前 AI 视频工具一直以来都没有解决的问题,只能通过后期配音解决。但是现在我可以直接在可灵做到了,这样我就不再需要再找人进行后期配音,而是一次性直接生成了完整、能够使用的镜头。
同时,我还尝试使用可灵 3.0 Omni 使用前面的素材做了一段替换主体的视频,把人物换成了我自己,
可灵 3.0 Omni 的视频编辑功能比 O1 要更加稳定,不管是风格的延续还是人物的动作和表情都会更加自然。更详细使用方法,大家可以参考我之前写的那篇关于 O1 的视频文章。
可灵做出来的多分镜不只局限于遵循我给的提示语,离谱的是,它能够在生成的过程中,自己补足我们在写提示语时可能没有写完整的部分。
它会把这一组镜头组合得非常完整,让这一组镜头就能完成单一场景的完整叙事。
这几天我看到了非常多的人,用两三句提示词,就做出了一段极具电影感,人物的表情,动作和配音几乎分不出是 AI 的作品。
最后,感谢你看到这里如果喜欢这篇文章,不妨顺手给我们点赞|在看|转发|评论

特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平台仅提供信息存储服务。
字节AI王炸Seedance2.0在海外火了!外国网友刷屏分享使用体验,直呼“这是最好的视频模型”,海外华人:物理表现更真实,模型算力很强大
手术过程中面罩意外砸眼,患者术后多种不适,复查发现右眼眼球有线头残留;院方承认面罩砸眼,会给予合理补偿
前大厂算法工程师,3家科技公司技术总监|致力打造最系统的Al学习体系,让1万人通过Al提高生产力
CATEGORIES
News
- 新疆察布查尔:塞锡湖呈现冰湖之星景观2026-02-11
- HuPuBREAKINGNEWS:广东宏远用张文逸张皓嘉和杜润旺交易得到雄鹿字母2026-02-11
- 多家银行调整代理上金所贵金属业务!啥信号?2026-02-11
- 塞古罗赢得葡萄牙总统选举2026-02-11
- 【同在国旗下】14年攻坚路:一面中国红闪耀月球梦2026-02-11
CONTACT US
Contact: 尊龙 人生就是博!登录专注AG发财网_尊龙人生就是博iAG发财网可以
Phone: 13800000000
Tel: 400-123-4567
E-mail: admin@youweb.com
Add: Here is your company address